Zhihan YangI'm a second-year PhD student at Cornell CS, where I focus on machine learning and specifically generative models. I have a BA in Mathematics and a BA in Statistics from Carleton College. During those years, I was fortunate to work with Seth Cooper on generative models, Anna Rafferty on bandits, Christopher Amato on deep reinforcement learning, and Adam Loy on MCMC algorithms. I received the CRA Outstanding Undergraduate Researcher Award. Email / GitHub / Google Scholar / LinkedIn |

|
ResearchCurrently, I'm interested in developing principled, controllable and efficient generative models for various modalities. |
|
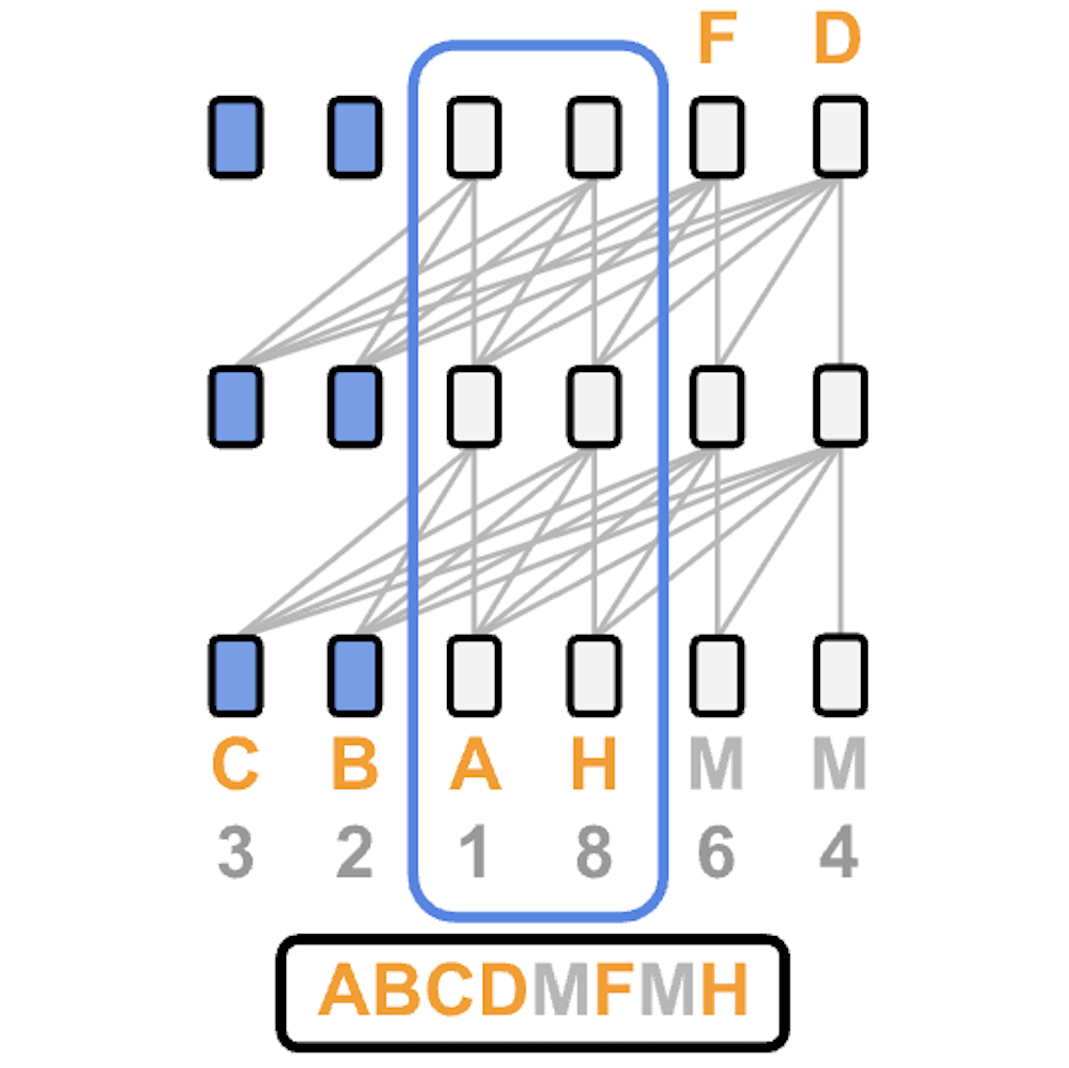
Esoteric Language ModelsSubham Sekhar Sahoo*, Zhihan Yang* (Joint First Authors), Yash Akhauri†, Johnna Liu†, Deepansha Singh†, Zhoujun Cheng† (Joint Second Authors), Zhengzhong Liu, Eric Xing, John Thickstun, Arash Vahdat arXiv, 2025 arxiv / code / website / twitter / We are the first to propose KV-caching for masked diffusion language models. |
|
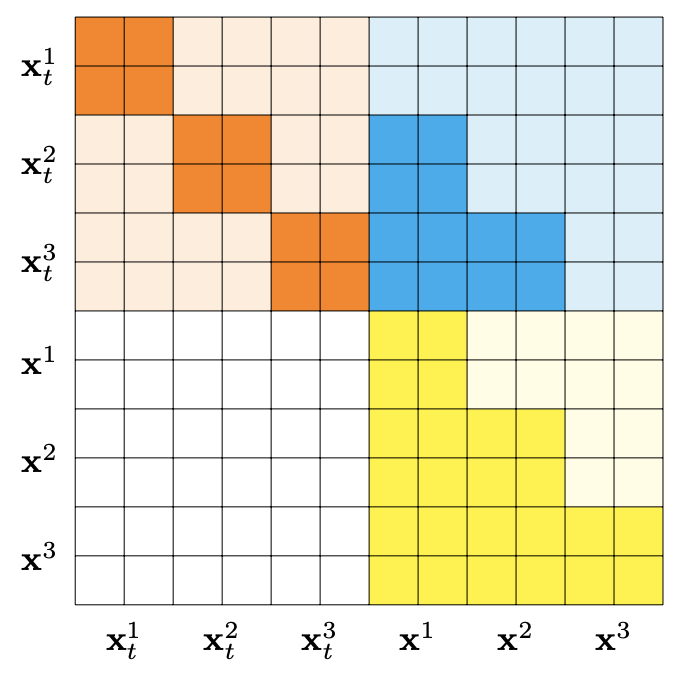
Block Diffusion: Interpolating Between Autoregressive and Diffusion Language ModelsMarianne Arriola, Aaron Gokaslan, Justin Chiu, Zhihan Yang, Zhixuan Qi, Jiaqi Han, Subham Sahoo, Volodymyr Kuleshov ICLR (Oral), 2025 arxiv / code / website / We introduce a class of block diffusion language models that interpolate between discrete denoising diffusion and autoregressive models. |
|
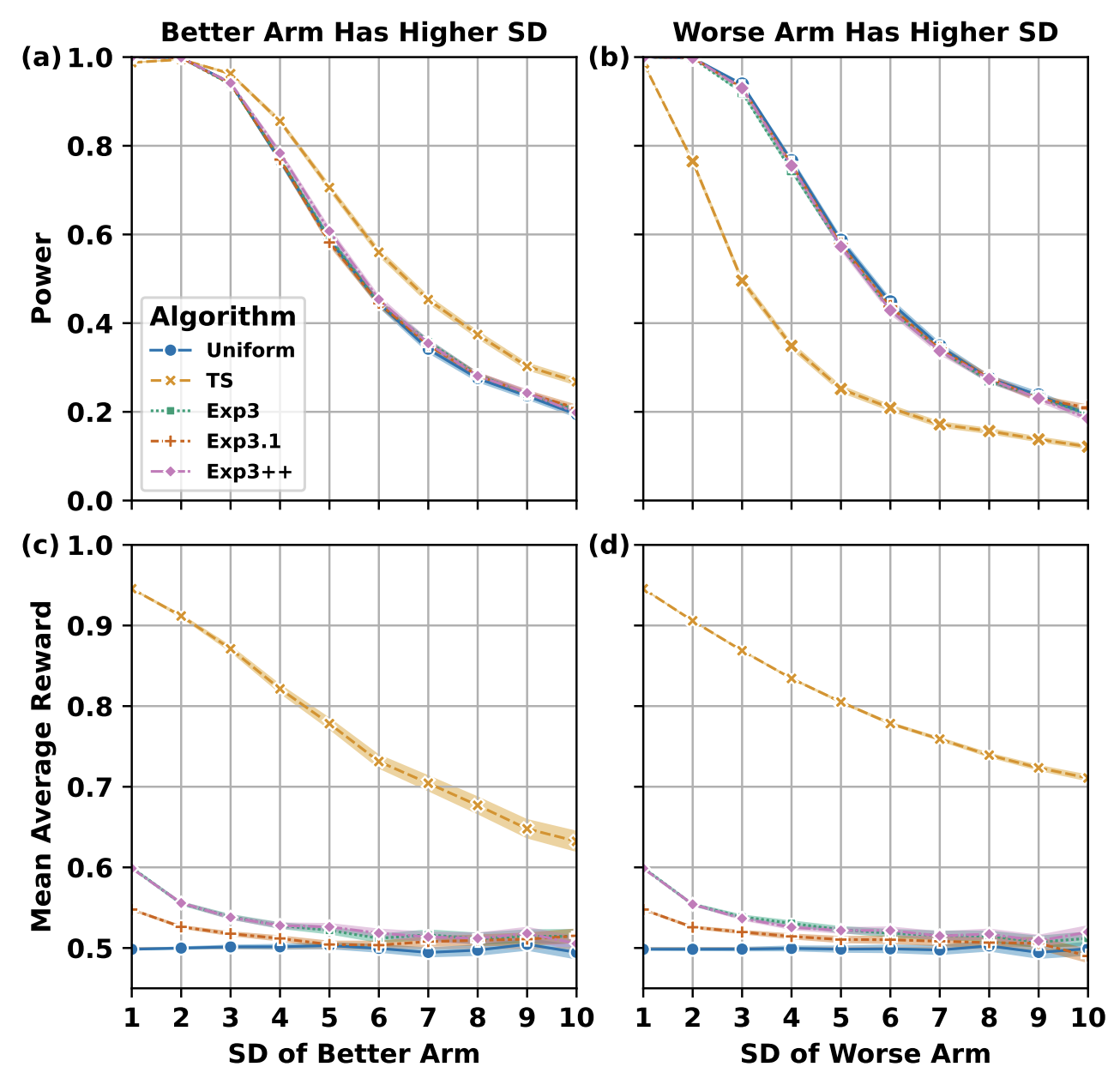
Adversarial Bandits for Drawing Generalizable Conclusions in Non-Adversarial Experiments: An Empirical StudyZhihan Yang, Shiyue Zhang, Anna Rafferty EDM (Short Paper), 2022 arxiv / code / website / We empirically analyse how adversarial bandit algorithms can enhance the reliability of conclusions drawn from large-scale educational experiments. |
|
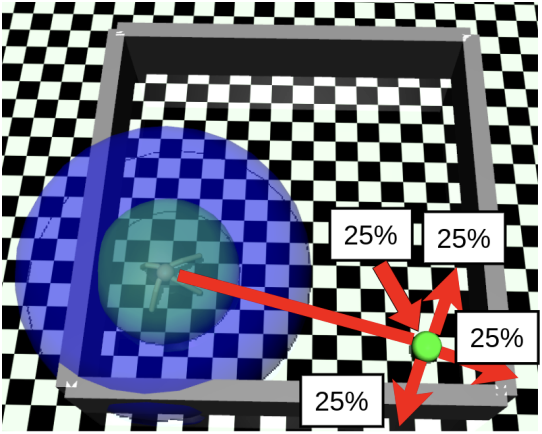
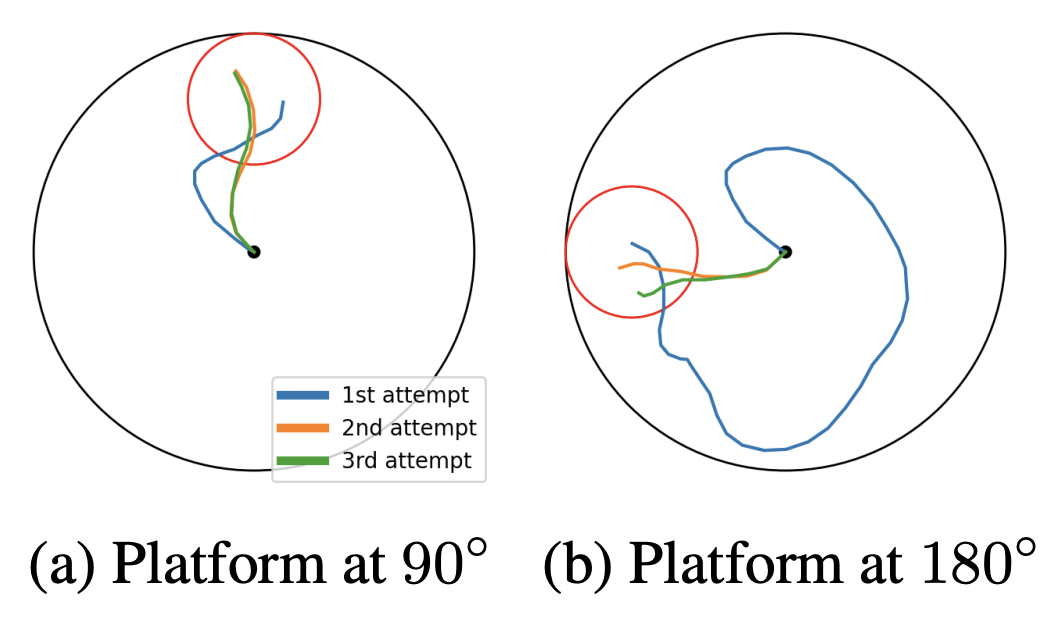
Hierarchical Reinforcement Learning under Mixed ObservabilityHai Nguyen*, Zhihan Yang* (Joint First Authors), Andrea Baisero, Xiao Ma, Robert Platt†, Christopher Amato† (Joint Senior Authors) WAFR, 2022 arxiv / website / We present a hierarchical RL framework that handles mixed observability settings, enabling modular policies that scale to complex robotic tasks. |
|
Recurrent Off-policy Baselines for Memory-based Continuous ControlZhihan Yang*, Hai Nguyen* (Joint First Authors) Deep RL Workshop @ NeurIPS, 2021 arxiv / code / We establish strong recurrent off-policy baselines for tasks requiring long-term memory. |
|
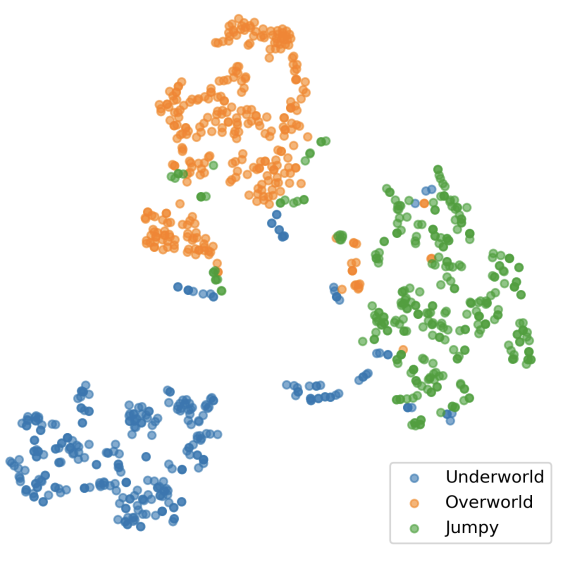
Game Level Clustering and Generation using Gaussian Mixture VAEsZhihan Yang, Anurag Sarkar, Seth Cooper AIIDE (Oral), 2020 arxiv / We leverage the Gaussian-Mixture VAE framework to cluster game levels in an unsupervised manner and synthesize novel game levels from the learned clusters. |
Other ProjectsUpcoming. |
|
Design and source code from Jon Barron's website |