Notes for Sutton & Barto Book (2018)
Here's my notes and Python implementation on some classical and deep RL algorithms mentioned in the book.
Chapter 4: Dynamic Programming
-
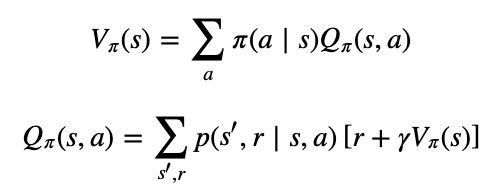
Fast Policy Iteration
With a focus on truncated policy iteration.
Chapter 5: Monte Carlo Methods
Chapter 6: Temporal-Difference Learning
-
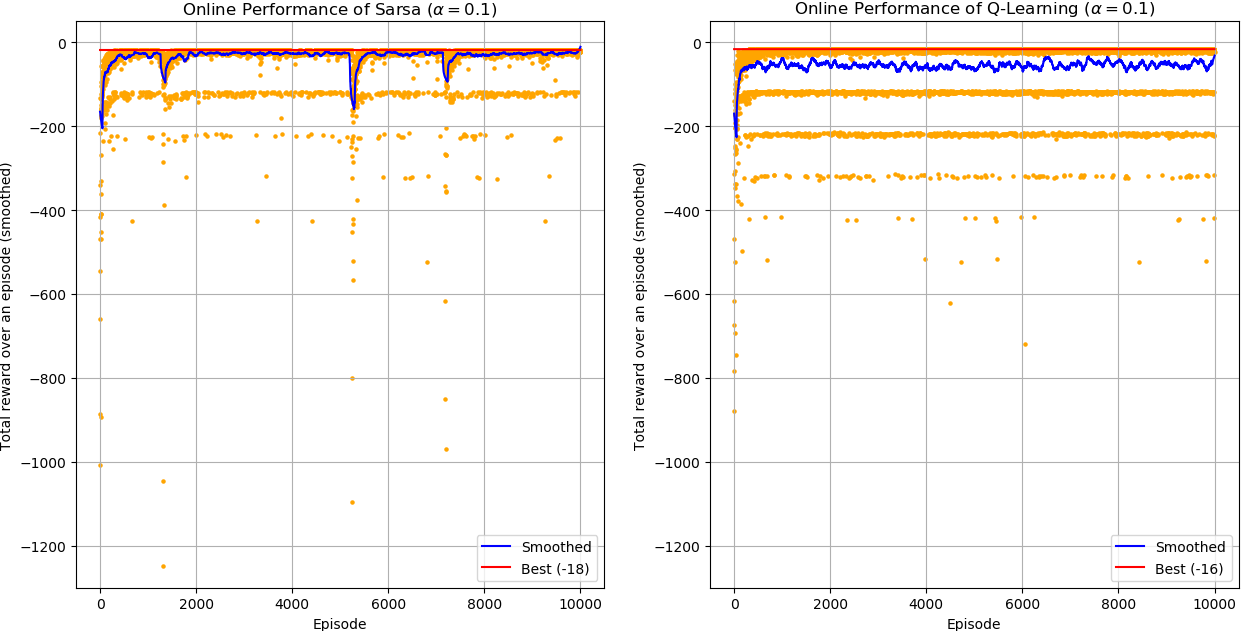
SARSA vs. Q-Learning
On-policy vs. off-policy algorithms for TD control.
Chapter 7: n-step Bootstrapping
Chapter 8: Planning and Learning with Tabular Methods
-
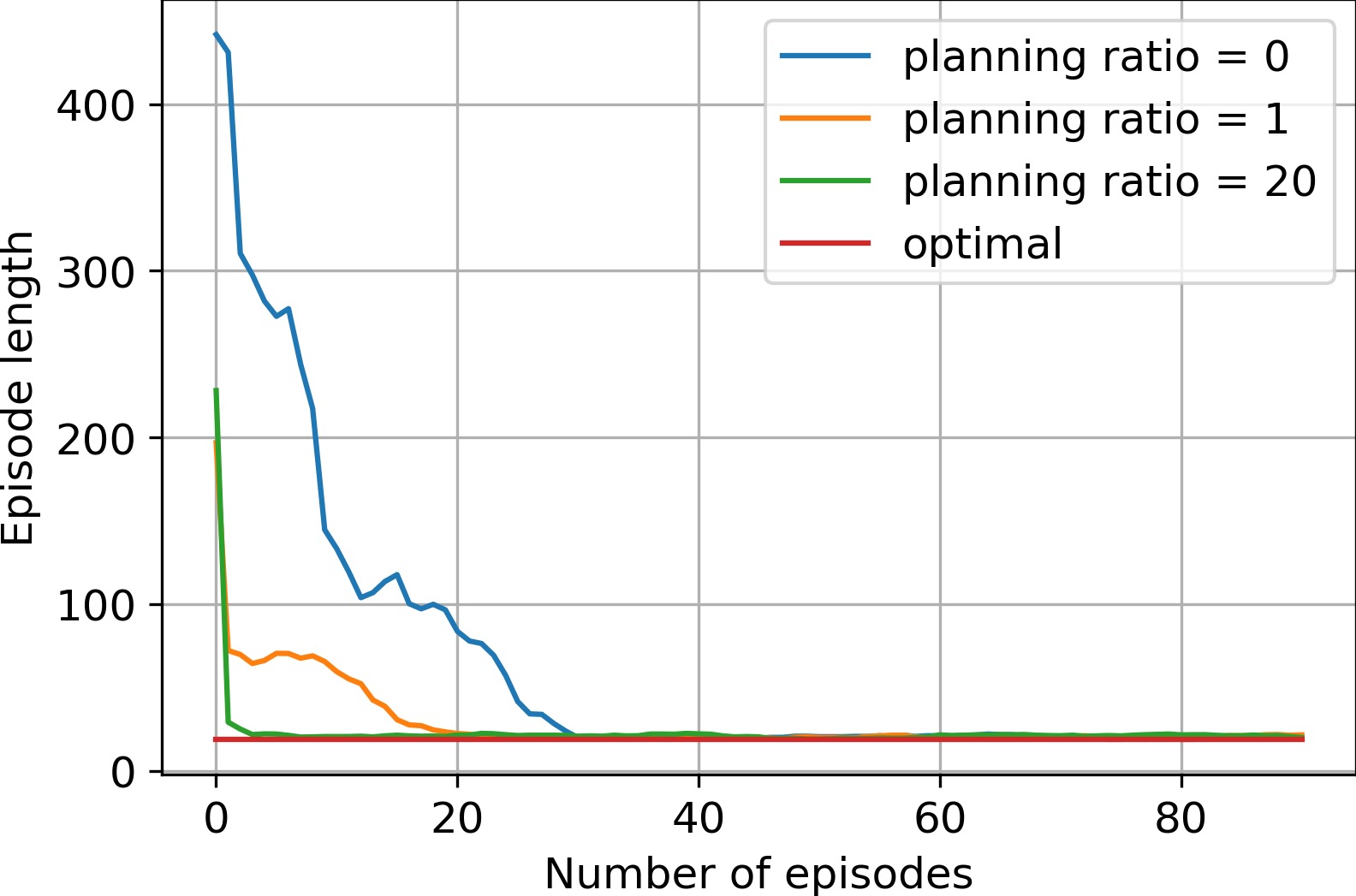
Dyna-Q
An introduction to planning using Q-learning.
-

Prioritized Sweeping
Improving the planning efficiency of DynaQ.
-

Rollout Algorithms
A method of decision-time planning tested on tic-tac-toe.
Chapter 9: On-policy Prediction with Approximation
-
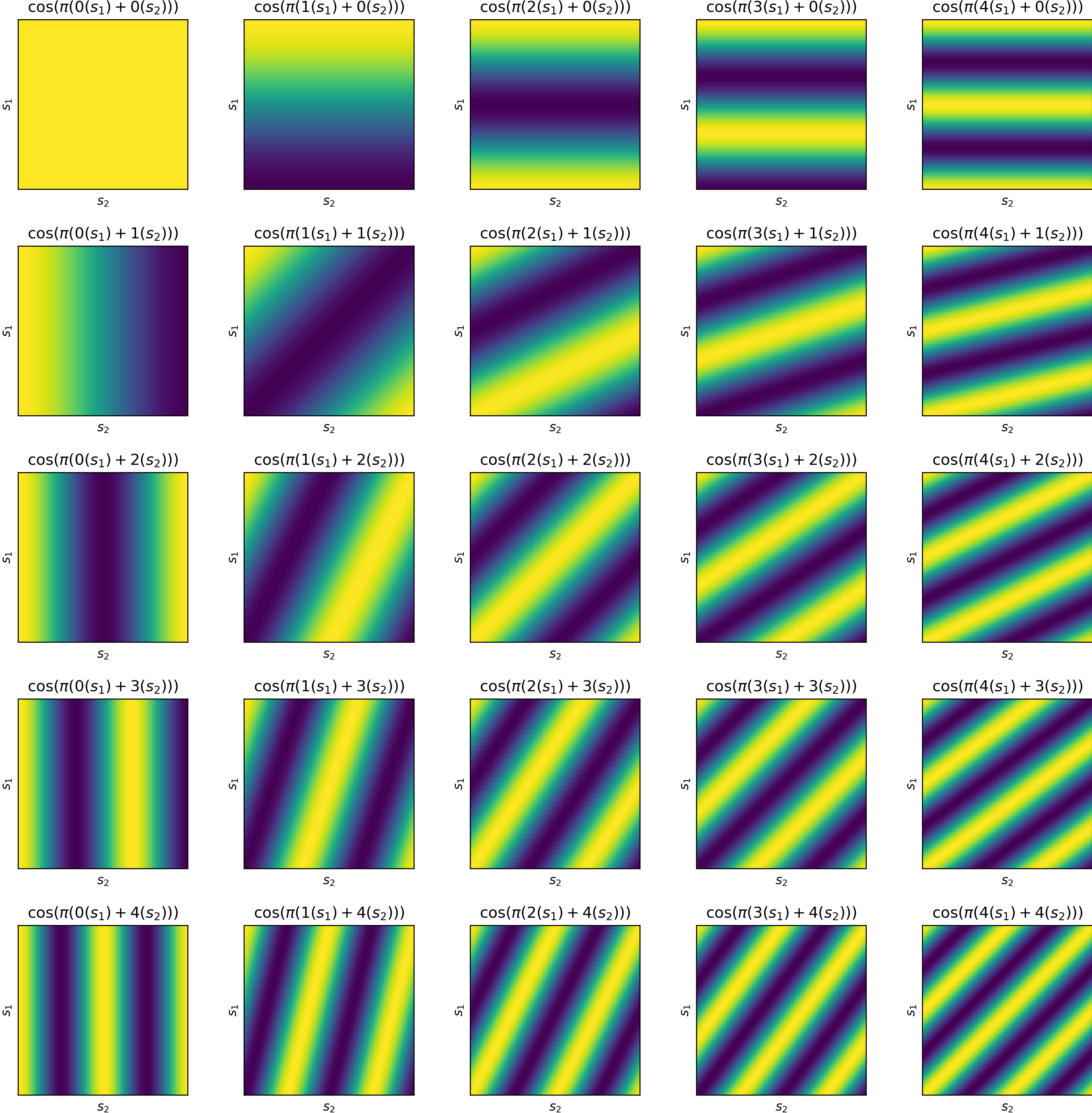
Gradient Monte-Carlo
On-policy prediction with Monte Carlo and linear approximator.
Chapter 9: On-policy Control with Approximation
-
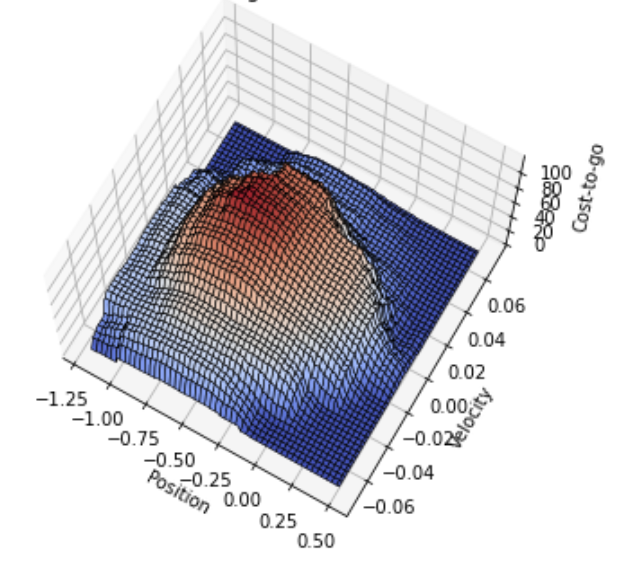
Semi-gradient SARSA
On-policy control with SARSA and linear approximator.